- 浏览: 59697 次
- 性别:

- 来自: 北京
-

最新评论
-
scu_cxh:
您好,我在学习hadoop方面的东西,想做一个对task监控的 ...
JobClient应用概述 -
bennie19870116:
看不到图呢...
Eclipse下配置使用Hadoop插件
一、环境
Hadoop 0.20.2、JDK 1.6、Linux操作系统
二、背景
上周五的时候,由于操作系统的原因,导致JDK出现莫名的段错误。无论是重启机器还是JDK重装都无济于事。更可悲的是,出问题的机器就是Master。当时心里就凉了半截,因为secondarynamenode配置也是在这个机器上(默认的,没改过)。不过万幸的是这个集群是测试环境,所以问题不大。借这个缘由,我将secondarynamenode重新配置到其他机器上,并做namenode挂掉并恢复的测试。
三、操作
1、关于secondarynamenode网上有写不错的文章做说明,这里我只是想说关键一点,它不是namenode的备份进程,说白了,namenode挂了,如果secondarynamenode没挂,很不幸,集群一样无法正常工作。这里有个文档翻译的很好,我链接一下:http://blog.csdn.net/AE86_FC/archive/2010/02/03/5284181.aspx
2、secondarynamenode一般来说不应该和namenode在一起,所以,我把它配置到了datanode上。配置到datanode上,一般来说需要改以下配置文件。conf/master、conf/hdfs-site.xml和conf/core-site.xml这3个配置文件,修改部分如下:
master:一般的安装手册都是说写上namenode机器的IP或是名称。这里要说明一下,这个master不决定哪个是namenode,而决定的是secondarynamenode(决定谁是namenode的关键配置是core-site.xml中的fs.default.name这个参数)。所以,这里直接写上你的datanode的IP或机器名称就可以了。一行一个。
hdfs-site.xml:这个配置文件要改1个参数:
0.0.0.0改为你的namenode的IP地址。
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
<description>
The
address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
core-site.xml:这里有2个参数可配置,但一般来说我们不做修改。fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。fs.checkpoint.size表示一次记录多大的size,默认64M。
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds
between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the
current edit log (in bytes) that triggers
a periodic checkpoint even
if the fs.checkpoint.period hasn't expired.
</description>
</property>
3、配置检查。配置完成之后,我们需要检查一下是否成功。我们可以通过查看运行secondarynamenode的机器上文件目录来确定是否成功配置。首先输入jps查看是否存在secondarynamenode进程。如果存在,在查看对应的目录下是否有备份记录。如下图:
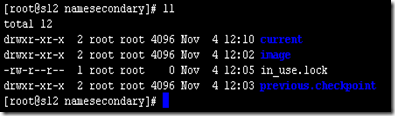
该目录一般存在于hadoop.tmp.dir/dfs/namesecondary/下面。
四、恢复
1、配置完成了,如何恢复。首先我们kill掉namenode进程,然后将hadoop.tmp.dir目录下的数据删除掉。制造master挂掉情况。
2、在配置参数dfs.name.dir指定的位置建立一个空文件夹; 把检查点目录的位置赋值给配置参数fs.checkpoint.dir; 启动NameNode,并加上-importCheckpoint。(这句话抄袭的是hadoop-0.20.2/hadoop-0.20.2/docs/cn/hdfs_user_guide.html#Secondary+NameNode,看看文档,有说明)
3、启动namenode的时候采用hadoop namenode –importCheckpoint
五、总结
1、secondarynamenode可以配置多个,master文件里面多写几个就可以。
2、千万记得如果要恢复数据是需要手动拷贝到namenode机器上的。不是自动的(参看上面写的恢复操作)。
3、镜像备份的周期时间是可以修改的,如果不想一个小时备份一次,可以改的时间短点。core-site.xml中的fs.checkpoint.period值。
4、写的不对或是有疑问的欢迎发邮件到dajuezhao@gmail.com


发表评论

-
Hadoop的基准测试工具使用(部分转载)
2011-01-21 11:58 1563一、背景由于以前没有� ... -
分布式集群中的硬件选择
2011-01-21 11:58 1000一、背景最近2个月时间一直在一个阴暗的地下室的角落里工作,主要 ... -
Map/Reduce的内存使用设置
2011-01-21 11:57 1608一、背景今天采用10台� ... -
Hadoop开发常用的InputFormat和OutputFormat(转)
2011-01-21 11:55 1455Hadoop中的Map Reduce框架依 ... -
Zookeeper分布式安装手册
2010-10-27 09:41 1295一、安装准备1、下载zookeeper-3.3.1,地址:ht ... -
Hadoop分布式安装
2010-10-27 09:41 981一、安装准备1、下载hadoop 0.20.2,地址:http ... -
Map/Reduce使用杂记
2010-10-27 09:40 905一、硬件环境1、CPU:Intel(R) Core(TM)2 ... -
Hadoop中自定义计数器
2010-10-27 09:40 1495一、环境1、hadoop 0.20.22、操作系统Linux二 ... -
Map/Reduce中的Partiotioner使用
2010-10-27 09:39 882一、环境1、hadoop 0.20.22� ... -
Map/Reduce中的Combiner的使用
2010-10-27 09:38 1153一、作用1、combiner最基本是实现本地key的聚合,对m ... -
Hadoop中DBInputFormat和DBOutputFormat使用
2010-10-27 09:38 2400一、背景 为了方便MapReduce直接访问关系型数据 ... -
Hadoop的MultipleOutputFormat使用
2010-10-27 09:37 1648一、背景 Hadoop的MapReduce中多文件输出默 ... -
Map/Reduce中公平调度器配置
2010-10-27 09:37 1507一、背景一般来说,JOB� ... -
无法启动Datanode的问题
2010-10-27 09:37 2364一、背景早上由于误删namenode上的hadoop文件夹,在 ... -
Map/Reduce的GroupingComparator排序简述
2010-10-27 09:36 1307一、背景排序对于MR来说是个核心内容,如何做好排序十分的重要, ... -
Map/Reduce中分区和分组的问题
2010-10-27 09:35 1102一、为什么写分区和分组在排序中的作用是不一样的,今天早上看书, ... -
关于Map和Reduce最大的并发数设置
2010-10-27 09:34 1214一、环境1、hadoop 0.20.22、操作系统 Linux ... -
关于集群数据负载均衡
2010-10-27 09:33 854一、环境1、hadoop 0.20.22、操作系统 Linux ... -
Map/Reduce执行流程简述
2010-10-27 09:33 957一、背景最近总在弄MR的东西,所以写点关于这个方面的内容,总结 ... -
Hadoop集群中关于SSH认证权限的问题
2010-10-27 09:32 866今天回北京了,想把在外地做的集群移植回来,需要修改ip地址和一 ...
相关推荐
SecondaryNameNode职责
NameNode及SecondaryNameNode分析
hdfs-secondarynamenode,nn2节点的作用,以及它的运行原理
第5章 NameNode和SecondaryNameNode(面试开发重点) 5.1 NN和2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应...
(1)第一次启动 NameNode 格式化后,创建 fsimage 和 edits 文件 (2)客户端对元数据进行增删改的请求 (3)NameNode 记录操作
今天小编就为大家分享一篇关于Hadoop中namenode和secondarynamenode工作机制讲解,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点(NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode),请注意分布式运行中的这几个结点的区别:从分布式存储的角度来说,...
DataNode SecondaryNameNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager 3. 配置集群 (1)核心配置文件 配置core-site.xml (2)HDFS配置文件 配置 hadoop-env.sh 配置 hadoop-site.xml...
HDFS的架构是较为经典的主/从架构,在架构图中NameNode是主节点,DataNode是从节点,HDFS Client是客户端、HDFS提供了比较丰富的客户端像cli、api、gui等等支持,SecondaryNameNode作为辅助NameNode工作的一个辅助...
DataNode SecondaryNameNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager 3. 配置集群 (1)核心配置文件 配置core-site.xml (2)HDFS配置文件 配置 hadoop-env.sh 配置 hadoop-site.xml...
hadoop-daemons.sh start secondarynamenode 单独启动SecondaryNameNode守护进程 hadoop-daemons.sh stop secondarynamenode 单独停⽌SecondaryNameNode守护进程 start-mapred.sh 启动Hadoop MapReduce守护进程...
Hadoop常见习题汇编,最新2018年版,仅供大家学习和交流使用,不得作为其他用途。
hadoop快速入门,hadoop安装及hadoop配置
SecondaryNameNode、ResourceManager、NodeManager 和 JobHistoryServer。 2. 在 Hadoop 集群主节点上搭建 MapReduce 开发环境 Eclipse。 3. 查看 Hadoop 自带的 MR-App 单词计数源代码 WordCount.java,在 Eclipse ...
在浏览器的地址栏输入:50090,进入页面可以查看SecondaryNameNode信息,如图;下面运行WordCount官方案例,统计data.txt文件中单词的出现频度。这个案例可以用来统计年度十大热销产品、年度风云人物、年度最热名词等...
也可以尝试将hadoop.dll和winutils.exe拷贝到bin目录下,NN命令添加:可以在start-dfs.cmd和stop-dfs.cmd中分别加入启动/关闭 secondarynamenode 的命令: start "Apache Hadoop Distribution" hadoop ...
a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 2. HDfS 中的 block 默认保存几份? a)3 份 b)2 份 c)1 份 d)不确定 3. 下列哪个程序通常与 NameNode 在一个节点启动? a)SecondaryNameNode ...
a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 2. HDfS 中的 block 默认保存几份? a)3 份 b)2 份 c)1 份 d)不确定 3. 下列哪个程序通常与 NameNode 在一个节点启动? a)SecondaryNameNode ...
SecondaryNameNode⼀般是 单独运⾏在⼀台机器上 SecondaryNameNode的⼯作情况: (1)SecondaryNameNode会定期和 NameNode通信,请求其停⽌使⽤EditLog ⽂件,暂时将新的写操作写到⼀个新的⽂件 edit.new上来,这个...
a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 2. HDfS 中的 block 默认保存几份? a)3 份 b)2 份 c)1 份 d)不确定 3. 下列哪个程序通常与 NameNode 在一个节点启动? a)SecondaryNameNode ...