
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 5592 | Accepted: 1925 |
Description
In a certain course, you take n tests. If you get ai out of bi questions correct on test i, your cumulative average is defined to be
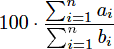 .
.
Given your test scores and a positive integer k, determine how high you can make your cumulative average if you are allowed to drop any k of your test scores.
Suppose you take 3 tests with scores of 5/5, 0/1, and 2/6. Without dropping any tests, your cumulative average is 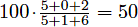 . However, if you drop the third test, your cumulative average becomes
. However, if you drop the third test, your cumulative average becomes 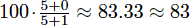 .
.
Input
The input test file will contain multiple test cases, each containing exactly three lines. The first line contains two integers, 1 ≤ n ≤ 1000 and 0 ≤ k < n. The second line contains n integers indicating ai for all i. The third line contains n positive integers indicating bi for all i. It is guaranteed that 0 ≤ ai ≤ bi ≤ 1, 000, 000, 000. The end-of-file is marked by a test case with n = k = 0 and should not be processed.
Output
For each test case, write a single line with the highest cumulative average possible after dropping k of the given test scores. The average should be rounded to the nearest integer.
Sample Input
3 1 5 0 2 5 1 6 4 2 1 2 7 9 5 6 7 9 0 0
Sample Output
83 100
Hint
To avoid ambiguities due to rounding errors, the judge tests have been constructed so that all answers are at least 0.001 away from a decision boundary (i.e., you can assume that the average is never 83.4997).
Source
题意:
给出 N (1 ~ 1000),K (0 ~ 1000000000)代表有 N 个科目的成绩,每个科目成绩都有 a,b 两种成绩,后给出 N 个 a 和 N 个 b 的成绩。现要使 y = 达到最大,当去除 K 个科目的成绩之后,y 最大能取到多大。
思路:
二分搜索。y = ,所以
100 * sigema(a) - y * sigema(b)
= 100 * (a1 + a2 + …… an) - y * (b1 + b2 + …… bn)
= (100 * a1 - y * b1)+ (100 * a2 - y * b2 ) + …… +(100 * an - y * bn)
= 0 ;
故枚举 y 后,先求出每个科目对应的 (100 * ai - y * bi) 值,后由大到小排序,取前面的 n - k 个。
若求和后的值 > 0,说明 y 小了,应该往右边搜,l = mid;
若求和后的值 < 0,说明 y 大了,应该往左边搜,r = mid;
若求和后的值 == 0,说明 y 的值刚刚好,但是可能还有更大的值出现,应该寻找最后一个满足条件的,所以应该往右边搜,l = mid。所以区间应该为左闭右开。
为什么要从大到小排序?
若从小到大排序的话,求和的结果 < 0 将会占大多数,那么二分搜索就不会不断往左边搜,使这个平均值越来越小,而题目要求的是求最大值。那么应该要让求和结果 > 0 占大多数,那么应该由大到小排序才对。
AC:
#include <cstdio>
#include <cstring>
#include <algorithm>
const int MAX = 1005;
using namespace std;
typedef long long ll;
int n, k;
double a[MAX], b[MAX], c[MAX];
int cmp (double i,double j) { return i > j; }
double Sort (double y) {
for (int i = 0; i < n; ++i)
c[i] = 100 * a[i] - y * b[i];
sort (c, c + n, cmp);
double ny = 0;
for (int i = 0; i < n - k; ++i)
ny += c[i];
return ny;
}
void solve () {
double l = 0, r = 100 + 1;
while (r - l > 0.001) {
double mid = l + (r - l) / 2;
double ny = Sort(mid);
if (ny >= 0) l = mid;
else r = mid;
}
printf("%.lf\n",l);
}
int main () {
while (~scanf("%d%d", &n, &k) && (n + k)) {
for (int i = 0; i < n; ++i)
scanf("%lf", &a[i]);
for (int i = 0; i < n; ++i)
scanf("%lf", &b[i]);
solve();
}
return 0;
}



相关推荐
各种数据结构、算法及实用的C#源...有足够多的鸡蛋时,可以采用二分查找法。有多于一个但数量有限的鸡蛋时,采用动态规划方法求解。双蛋问题 (two-egg problem) 是本问题的一个特例,曾出现于谷歌的程序员面试题中。
Dropping-Thunder:Dropping Thunders TD模拟器
JavaScript
textlint-rule-no-dropping-i这是一个检测丢失单词的规则。 are我们正在发展。 developing我在发展。安装npm install @textlint-ja/textlint-rule-no-dropping-i用法将@textlint-ja/textlint-rule-no-dropping-i ....
BallDropping是一个会让人上瘾的噪音制造器,如果平时无聊的时候也可以当作小游戏来玩。很多小球从天而降,根据碰击角度、速度的不同,掉在鼠标划的线上会发出大珠小珠落玉盘的声音。 <br>你可不要小看了...
gps测试,jieshougps数据存储数据库,检测发送命令地
语言:English通过空中景观放下苹果,绝对不会错过重要的掉苹果活动,例如小睡放苹果可以帮助您与商店的预购开店保持最新并保持个人时间表...使用Airscape的Dropping Apple绝不会错过重要的Apple Droping事件,例如小睡
人が来れないんです安装npm install textlint-rule-no-dropping-the-ra用法将“ no-drop-the-ra” .textlintrc { " rules " : { " no-dropping-the-ra " : true }}贡献叉吧! 创建功能分支: git checkout -b my-new...
Call dropping performance analysis of the eNB-first channel access policy in LTE-Advanced relay networks
偏好(或批准)投票表以选择选举竞赛的优胜者或排名决定。 使用丢弃成本最小化来组合两种Condorcet方法:克隆Schwartz顺序丢弃和Tideman的排名对。
This paper is concerned with the distributed fusion estimation in sensor networks where local estimates are sent to a fusion centre for fusion estimation, with random delays and packet dropouts....
Compiled library that adds support for your site visitors to login with their OpenIDs by just dropping an ASP.NET control onto your page. It's that easy. An AJAX-style OpenID Selector control is also ...
TCL script to find wireless packet dropping nodes2609002STC12C5A60S2+2.4TFT+DS1302+DS18B20+GPS+FM 自动校时收音机电子钟 STC12C5A60S2+2.4TFT+DS1302+DS18B20+GPS+FM 自动校时收音机电子钟 捣鼓了许久
2D滴入式软体 自学项目我一直对计算机模拟物理世界充满热情。 最近,我试图在二维中模拟与刚体碰撞时的软体变形。 该程序仍未完成,但是现在我将其留在这里,过一会儿我将返回它。
中文版文档 Emoji Rain Hey, it's raining emoji! This is a really simple and funny animation for Android. You could find similar ...How many emojis will dropping in each flow, default 6 duration
35个用户在1000time slot中,以0.2的概率产生packets
抛球游戏 827游戏的第一款游戏
当VirtualBox 2.1.4升级到2.2.0以后,突然发现虚拟的系统无法使用主机的网络上网了,google了一下,发现很多人碰到这个问题,但没有解决办法,甚至有人认为是VirtualBox的Bug,其实不然。 经过研究发现,2.2.0缺省...
基于Python和Linux的自主无人机,以及使用React和Flask开发的控制Web应用程序 无人机可以使用提交给任务飞行脚本的参数进行种子种植任务-列,行,高度,间距。 它通过Raspberry Pi USB连接和pyserial将下降信号发送...
Delphi written try dropping bombs on game